معماری ریزپردازنده Intel Core i9
تحلیل جامع معماری، بهینهسازیها و قابلیتهای نسلهای مختلف
۱. مقدمه
۱.۱. پیشینه و تاریخچه
سری پردازندههای Intel Core i9 به عنوان پرچمدار محصولات Intel برای کاربران حرفهای و پرعملکرد طراحی شدهاند. این پردازندهها از معماریهای پیشرفتهای همچون Skylake، Coffee Lake، Comet Lake، Rocket Lake، Alder Lake و Raptor Lake بهره میبرند. نسل اول Core i9 در سال ۲۰۱۷ معرفی شد و هدف آن ارائه بالاترین سطح عملکرد در پلتفرمهای Desktop و Mobile بود.
معماری Core i9 ترکیبی از تکنولوژیهای پیشرفته شامل Out-of-Order Execution، Hyper-Threading، پیشبینی شاخه پیشرفته، و سلسله مراتب حافظه نهان چند سطحی را در خود جای داده است. این پردازندهها با بهرهگیری از فرآیندهای ساخت پیشرفته (از 14nm تا 7nm Intel) و معماریهای بهینهشده، توانستهاند رکوردهای جدیدی در زمینه عملکرد تکهستهای و چندهستهای برقرار کنند.

معماری Alder Lake نسل 12 - اولین پردازنده Hybrid Intel با 8 P-cores و 8 E-cores
Core i9-12900K: 16 هسته (8P+8E) / 24 رشته / 30MB L3

دیاگرام بلوکی پردازنده Intel - اجزای اصلی و ارتباطات
| نسل | معماری | فرآیند ساخت | تعداد هسته | L3 Cache | TDP | Max Turbo |
|---|---|---|---|---|---|---|
| ۱st Gen (2017) | Skylake-X | 14nm | 10-18 | 13.75-24.75 MB | 165W | 4.5 GHz |
| 8th Gen (2018) | Coffee Lake | 14nm++ | 8 | 16 MB | 95W | 5.0 GHz |
| 9th Gen (2018) | Coffee Lake Refresh | 14nm++ | 8 | 16 MB | 95-127W | 5.0 GHz |
| 10th Gen (2020) | Comet Lake | 14nm+++ | 10 | 20 MB | 125W | 5.3 GHz |
| 12th Gen (2021) | Alder Lake | Intel 7 (10nm) | 16 (8P+8E) | 30 MB | 125W | 5.2 GHz |
| 13th Gen (2022) | Raptor Lake | Intel 7 | 24 (8P+16E) | 36 MB | 125W | 5.8 GHz |
نکته: نسلهای ۱۲ و ۱۳ از معماری Hybrid استفاده میکنند که شامل هستههای Performance (P-cores) و Efficient (E-cores) است. TDP واقعی در بار کاری سنگین میتواند تا ۲۵۳W برسد.

معماری Raptor Lake (نسل 13) - Core i9-13900K
24 هسته (8P+16E) / 32 رشته / 36MB L3 / 52MB Total Cache
پردازنده Intel Core i9 نسل 13 - معماری Hybrid با 24 هسته
(نمایش مشخصات واقعی پردازنده)
بلوک دیاگرام عمومی پردازنده - نمایش اجزای اصلی
دیاگرام معماری پردازندههای Intel Core - نمایش کامل اجزای مختلف
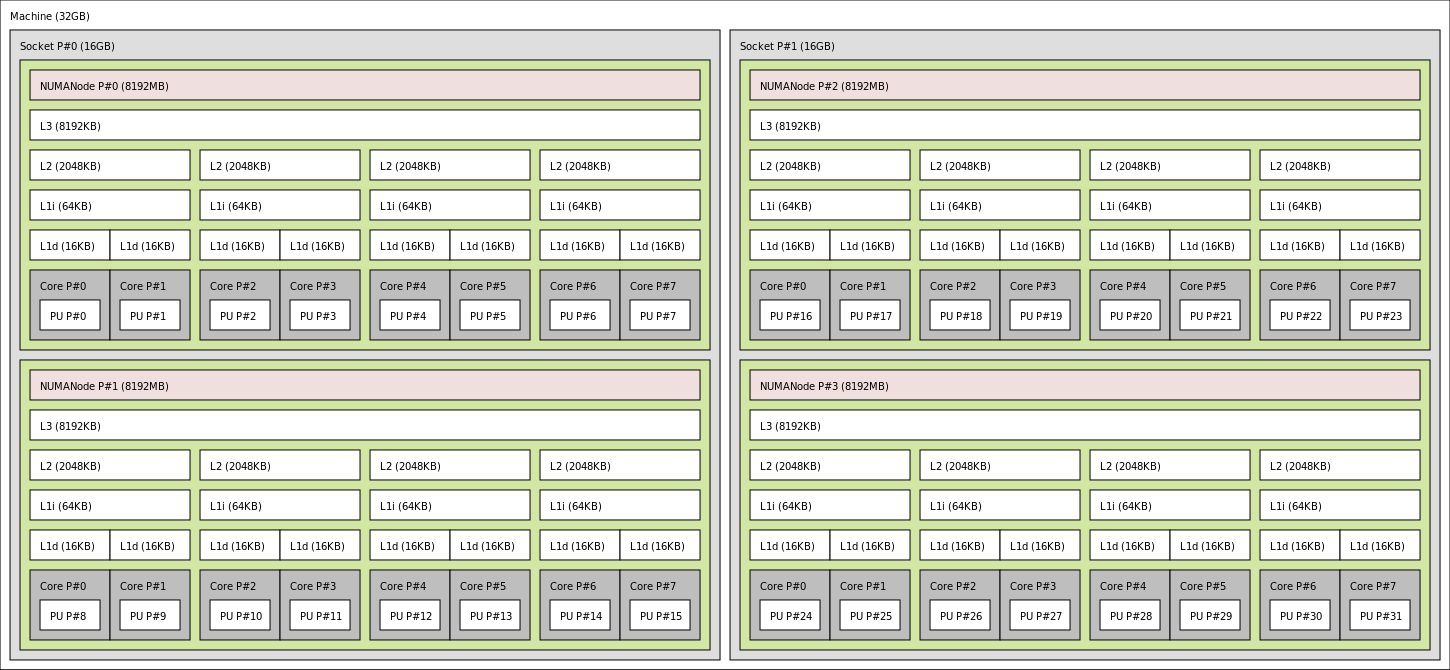
نمای کلی توپولوژی سیستم - نمایش هستهها، Cache و سلسله مراتب حافظه
۱.۲. مفاهیم پایه معماری پردازنده

معماری فون نویمان - اساس پردازندههای مدرن
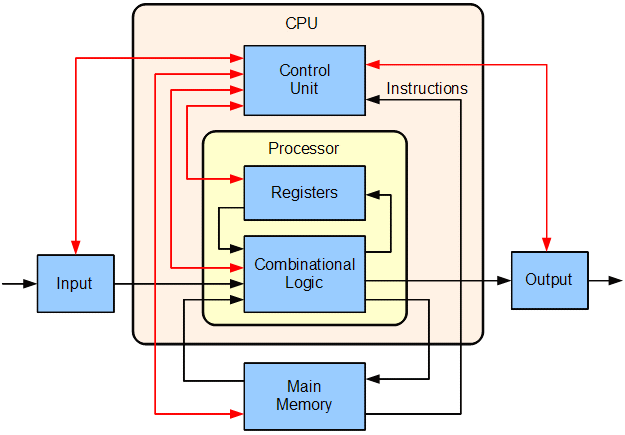
نمودار بلوکی کامپیوتر - اجزای اصلی و ارتباطات
مفاهیم کلیدی:
• Pipeline (خط لوله):
تقسیم اجرای دستورالعملها به مراحل مختلف برای افزایش Throughput و اجرای همزمان چندین دستور.
• Out-of-Order Execution:
قابلیت اجرای دستورالعملها به ترتیبی غیر از ترتیب برنامه برای بهرهوری بهتر از منابع.
• Superscalar Architecture:
توانایی اجرای بیش از یک دستور در هر سیکل ساعت با استفاده از واحدهای اجرایی متعدد.
• Cache Hierarchy:
سلسله مراتب حافظههای نهان با سرعتها و اندازههای مختلف برای کاهش تأخیر دسترسی به داده.
مقایسه تعاملی نسلهای Core i9
۲. نمای کلی معماری
۲.۱. دیاگرام بلوکی هسته
معماری Core i9 شامل واحدهای اصلی زیر است:
- Front-End: واحد واکشی و رمزگشایی دستورالعملها
- Execution Engine: واحدهای اجرایی شامل ALU، FPU، SIMD
- Memory Subsystem: سلسله مراتب حافظه نهان و کنترلر حافظه
- Uncore: Ring Bus، LLC و کنترلرهای I/O
نکته:
معماریهای نسلهای جدیدتر (Alder Lake و Raptor Lake) از طراحی Hybrid استفاده میکنند که شامل هستههای Performance (P-cores) و Efficient (E-cores) هستند.
۳. معماری خط لوله (Pipeline)
۳.۱. مراحل Pipeline
Core i9 از یک pipeline عمیق و پیچیده با قابلیت Out-of-Order Execution استفاده میکند:
- Fetch:واکشی دستورالعملها از L1-I Cache با پهنای باند بالا (16-32 byte/cycle)
- Decode:رمزگشایی دستورالعملهای x86 پیچیده به Micro-Ops (μOps)
- μOp Cache:ذخیره μOps رمزگشایی شده برای کاهش تأخیر Decode
- Allocate:تخصیص منابع (ROB، RS) به μOps
- Schedule:زمانبندی خارج از ترتیب برای اجرا
- Execute:اجرای μOps در واحدهای اجرایی متعدد
- Retire:Commit نتایج به ترتیب برنامه
۳.۲. Pipeline Stalls و Hazards
عوامل مختلفی میتوانند باعث توقف یا کاهش کارایی Pipeline شوند:
وابستگی دادهها (Data Dependencies)
تکنیکهای مقابله:
- Register Renaming: حذف WAR و WAW dependencies با استفاده از Physical Register File (180+ registers)
- Forwarding: انتقال مستقیم نتایج بین واحدهای اجرایی
- Out-of-Order Execution: اجرای دستورالعملهای مستقل در حین انتظار
- Memory Disambiguation: پیشبینی وابستگیهای حافظه
۴. پیشبینی شاخه (Branch Prediction)
پیشبینی شاخه یکی از حیاتیترین اجزای معماریهای مدرن است. Core i9 از یک سیستم پیشبینی چند لایه و پیچیده استفاده میکند که دقت بالای 97-99% را در کاربردهای واقعی ارائه میدهد.
۴.۱. مؤلفههای Branch Predictor
- Size: 4K-12K entries
- Function: ذخیره آدرس مقصد شاخههای شناخته شده
- Latency: دسترسی در یک چرخه
- Organization: ساختار Set-Associative
- Algorithm: Two-Level Adaptive Predictor
- Global History: تاریخچه چندین شاخه اخیر
- Local History: تاریخچه هر شاخه خاص
- Counters: 2-bit Saturating Counters
- Purpose: پیشبینی آدرس بازگشت از توابع
- Depth: 16-32 entries
- Structure: Stack (LIFO)
- Accuracy: تقریباً 100% برای call/return معمولی
- Target: شاخههای غیرمستقیم (virtual functions، function pointers)
- Method: Target History + Correlation
- Complexity: چالشبرانگیزترین نوع شاخه
۴.۲. الگوریتم پیشبینی TAGE
TAGE (TAgged GEometric history length predictor) یکی از پیشرفتهترین الگوریتمهای پیشبینی شاخه است که در معماریهای جدید Intel استفاده میشود:
- استفاده از چندین جدول با طولهای مختلف تاریخچه
- Tag-based indexing برای کاهش Aliasing
- Geometric history lengths: h(i) = α^i × L
- Usefulness counters برای مدیریت جایگزینی
۵. سلسله مراتب حافظه نهان
Core i9 از یک سیستم حافظه نهان سه یا چهار سطحی استفاده میکند که برای کاهش تأخیر دسترسی به حافظه بهینه شده است.
| سطح | نوع | اندازه | Latency |
|---|---|---|---|
| L1-I | Instruction | 32 KB | 4-5 cycles |
| L1-D | Data | 32-48 KB | 4-5 cycles |
| L2 | Unified | 256 KB - 2 MB | 12-14 cycles |
| L3 (LLC) | Unified | 16-36 MB | 40-50 cycles |
| L4 (eDRAM) | Unified | 128 MB | ~60 cycles |
۵.۱. پروتکلهای Coherency
پروتکل MESIF (بهبودیافته از MESI) برای حفظ سازگاری حافظه نهان در سیستمهای چند هستهای:
- M (Modified): داده تغییر کرده و فقط در این Cache موجود است
- E (Exclusive): داده تمیز و فقط در این Cache موجود است
- S (Shared): داده در چندین Cache موجود است
- I (Invalid): داده معتبر نیست
- F (Forward): داده Shared است اما این Cache مسئول پاسخدهی است (کاهش ترافیک)
تأخیر دسترسی به سطوح مختلف حافظه
نکته: هرچه به سطوح پایینتر حافظه میرویم، تأخیر به صورت نمایی افزایش مییابد. L1 Cache تقریباً ۵۰ برابر سریعتر از RAM است.
۶. واحدهای اجرایی
Core i9 دارای تعداد زیادی واحد اجرایی تخصصی است که به صورت موازی کار میکنند.
- ALU (Arithmetic Logic Unit):
- 4-6 واحد ALU کامل
- پشتیبانی از عملیات 8 تا 64 بیتی
- Latency: 1 cycle برای اکثر عملیات
- Throughput: 4-6 ops/cycle
- Address Generation Unit (AGU):
- 2-3 واحد AGU برای Load
- 1-2 واحد AGU برای Store
- محاسبه آدرسهای پیچیده (base + index*scale + displacement)
- Branch Unit:
- ارزیابی شرایط شاخه
- محاسبه آدرس مقصد
- بررسی صحت پیشبینی
- FPU (Floating Point Unit):
- 2-3 واحد FP برای ADD/SUB
- 2-3 واحد FP برای MUL
- 1-2 واحد FP برای DIV/SQRT
- پشتیبانی از FP32, FP64, FP80
- SIMD Units (AVX-512):
- 2 واحد 512-bit FMA (Fused Multiply-Add)
- عملیات روی 16× FP32 یا 8× FP64 به صورت موازی
- Throughput: 2× 512-bit ops/cycle
- 32 رجیستر ZMM (512-bit)
- Special Instructions:
- AES-NI: رمزنگاری سختافزاری
- SHA Extensions: Hash محاسبات
- AVX-VNNI: Deep Learning
۶.۱. Execution Ports
توزیع واحدهای اجرایی بر روی Port ها (مثال: Ice Lake/Tiger Lake):
۷. قابلیتها و بهینهسازیهای پیشرفته
اجرای همزمان دو Thread روی یک هسته فیزیکی با اشتراکگذاری منابع اجرایی:
- هر Thread دارای Register File و Architectural State مستقل
- اشتراک Cache، Execution Units، و Pipeline resources
- بهرهوری تا 30% در workload های مناسب
- Overhead کم: کمتر از 5% افزایش مساحت تراشه
افزایش دینامیک فرکانس بر اساس شرایط حرارتی و توان:
- Turbo Boost 2.0: افزایش فرکانس تا 400-600 MHz بالاتر از Base
- Turbo Boost Max 3.0: شناسایی بهترین هستهها و اختصاص workload های single-thread
- Adaptive Boost: Multi-core turbo بهبودیافته
- مانیتورینگ لحظهای دما، جریان، و توان
- Prefetchers: 4 سطح prefetcher (L1, L2, LLC, MLC Streamer)
- Memory Controller: پشتیبانی از DDR4/DDR5 با پهنای باند بالا
- Load/Store Optimization: Store-to-Load Forwarding، Memory Disambiguation
- TLB Hierarchy: L1 DTLB (64 entries), L2 STLB (1536 entries)
- C-States: حالتهای مختلف صرفهجویی انرژی (C0 تا C10)
- P-States: سطوح مختلف فرکانس و ولتاژ
- Power Gating: خاموش کردن واحدهای غیرفعال
- FIVR: رگولاتور ولتاژ داخلی برای کنترل دقیق
۸. تحلیل عملکرد
۸.۱. معیارهای کلیدی
3.5 - 4.5
در workload های بهینه شده با OoO execution و branch prediction موفق
50-100+ GB/s
بسته به تعداد کانالهای حافظه و نوع DRAM (DDR4/DDR5)
1-2+ TFLOPS
با استفاده کامل از واحدهای AVX-512 در تمام هستهها
۸.۲. عوامل محدودکننده عملکرد
عملکرد محدود به پهنای باند یا تأخیر حافظه:
- Cache miss های مکرر به LLC یا DRAM
- Random memory access patterns
- الگوهای دسترسی با Stride نامنظم
- راهحل: بهینهسازی data locality، استفاده از prefetch، blocking
۹. نتیجهگیری
معماری Intel Core i9 نمونهای از پیچیدگی و توان محاسباتی پردازندههای مدرن است. ترکیب تکنیکهای پیشرفته شامل Out-of-Order Execution عمیق، پیشبینی شاخه دقیق، سلسله مراتب حافظه نهان بهینه، و واحدهای اجرایی گسترده امکان دستیابی به عملکرد بالا در طیف وسیعی از کاربردها را فراهم میکند.
درک این معماری برای بهینهسازی نرمافزار، تحلیل عملکرد، و طراحی الگوریتمهای کارآمد ضروری است. نسلهای جدیدتر با معرفی هستههای Hybrid (P-core و E-core) و بهبودهای مداوم در فرآیند ساخت و معماری، مرزهای عملکرد را به جلو میبرند.
واژهنامه اصطلاحات فنی
در این بخش، تمام اصطلاحات فنی و تخصصی که در متن مقاله آمدهاند، به زبان ساده توضیح داده شدهاند.
Skylake, Coffee Lake, Comet Lake, Rocket Lake, Alder Lake, Raptor Lake
تعریف: نامهای نسلهای مختلف معماری پردازندههای Intel. هر نام نشاندهنده یک نسل خاص با بهبودها و ویژگیهای جدید است.
مثال: Skylake نسل اول (2015)، Raptor Lake جدیدترین نسل (2022-2023) است.
Out-of-Order Execution (OoO)
تعریف: تکنیکی که پردازنده دستورات را به ترتیبی غیر از ترتیب برنامه اجرا میکند تا از منابع به طور بهینه استفاده شود.
مثال: اگر دستور 1 منتظر داده از حافظه باشد، پردازنده دستور 2 و 3 را زودتر اجرا میکند.
فایده: افزایش سرعت اجرا با پر کردن زمانهای بیکاری پردازنده.
Hyper-Threading (HT)
تعریف: تکنولوژی Intel که یک هسته فیزیکی را به دو هسته منطقی (Thread) تبدیل میکند.
مثال: پردازنده 8 هستهای با HT میتواند 16 Thread همزمان اجرا کند.
فایده: افزایش کارایی با اجرای همزمان بیشتر برنامهها.
Pipeline
تعریف: تقسیم فرآیند اجرای دستور به مراحل کوچکتر (مثل خط تولید کارخانه) برای افزایش سرعت.
مراحل: Fetch (واکشی دستور) → Decode (رمزگشایی) → Execute (اجرا) → Write-back (نوشتن نتیجه)
فایده: امکان اجرای همزمان چندین دستور در مراحل مختلف.
Hybrid Architecture
تعریف: ترکیب دو نوع هسته: Performance Cores (P-cores) برای کارهای سنگین و Efficiency Cores (E-cores) برای کارهای سبک.
مثال: Core i9-13900K دارای 8 هسته P-core و 16 هسته E-core است.
فایده: تعادل بین عملکرد بالا و مصرف انرژی پایین.
P-cores (Performance Cores)
تعریف: هستههای قدرتمند با فرکانس بالا برای کارهای سنگین محاسباتی.
ویژگی: دارای Hyper-Threading، سرعت بالا، مصرف برق بیشتر.
کاربرد: بازیها، نرمافزارهای حرفهای، کامپایل.
E-cores (Efficiency Cores)
تعریف: هستههای کممصرف برای کارهای پسزمینه و چندوظیفهای.
ویژگی: بدون Hyper-Threading، مصرف برق کمتر، فرکانس پایینتر.
کاربرد: وظایف پسزمینه، مرورگر، برنامههای ساده.
Cache (حافظه نهان)
تعریف: حافظهای بسیار سریع و کوچک بین CPU و RAM برای ذخیره دادههای پرکاربرد.
سطوح: L1 (سریعترین، کوچکترین) → L2 → L3 (کندتر، بزرگتر)
فایده: کاهش زمان انتظار CPU برای دریافت داده از RAM.
L1, L2, L3 Cache
L1: سریعترین (4-5 سیکل)، کوچکترین (32-96 KB)، اختصاصی هر هسته.
L2: سرعت متوسط (12-15 سیکل)، اندازه متوسط (256KB-2MB)، اختصاصی هر هسته یا مشترک بین چند هسته.
L3: کندتر (40-50 سیکل)، بزرگتر (8-36 MB)، مشترک بین همه هستهها.
TLB (Translation Lookaside Buffer)
تعریف: حافظه نهان ویژه برای ذخیره ترجمه آدرسهای مجازی به فیزیکی.
فایده: سرعت بخشیدن به فرآیند ترجمه آدرس حافظه.
نمونه: L1 DTLB: 64 ورودی، L2 STLB: 1536 ورودی.
Prefetcher
تعریف: مکانیزمی که دادههای احتمالی مورد نیاز آینده را پیش از درخواست به Cache میآورد.
سطوح: L1, L2, L3 (LLC), MLC Streamer
فایده: کاهش Cache Miss و افزایش سرعت دسترسی به داده.
MESIF Protocol
تعریف: پروتکل هماهنگی Cache در سیستمهای چندهستهای (نسخه بهبود یافته MESI).
حالتها: Modified (تغییر یافته), Exclusive (انحصاری), Shared (مشترک), Invalid (نامعتبر), Forward (ارسالکننده)
فایده: اطمینان از یکسان بودن دادهها در Cache های مختلف.
14nm, 10nm, 7nm (فرآیند ساخت)
تعریف: اندازه ترانزیستورها در پردازنده (نانومتر = یک میلیاردم متر).
قانون: عدد کوچکتر = ترانزیستورهای کوچکتر = مصرف برق کمتر + سرعت بیشتر + حرارت کمتر
مثال: Intel 7 (10nm SuperFin) فرآیند پیشرفتهتر از 14nm است.
TDP (Thermal Design Power)
تعریف: حداکثر مقدار حرارتی که پردازنده تولید میکند و سیستم خنککننده باید دفع کند (بر حسب وات).
مثال: Core i9-13900K: TDP پایه 125W، حداکثر در Turbo: 253W
کاربرد: انتخاب خنککننده و منبع تغذیه مناسب.
Turbo Boost
تعریف: تکنولوژی افزایش خودکار فرکانس پردازنده فراتر از سرعت پایه در صورت نیاز و وجود ظرفیت حرارتی.
مثال: Core i9 از 3.0 GHz پایه به 5.8 GHz Turbo میرسد.
شرایط: دمای پایین، مصرف برق کافی، بار کاری مناسب.
IPC (Instructions Per Cycle)
تعریف: تعداد دستورات اجرا شده در هر سیکل ساعت پردازنده.
اهمیت: معیار کارایی معماری - IPC بالاتر = پردازنده کارآمدتر
مثال: Core i9 مدرن: 3.5-4.5 IPC در بارکاری بهینه.
DDR4, DDR5 (DRAM)
تعریف: نوع حافظه اصلی سیستم (RAM).
DDR4: نسل قدیمیتر، سرعت تا 3200 MHz، ولتاژ 1.2V
DDR5: جدیدترین نسل، سرعت 4800-5600 MHz+، ولتاژ 1.1V، پهنای باند بیشتر
پشتیبانی: Core i9-12th Gen و بالاتر از هر دو نوع پشتیبانی میکنند.
PCIe (PCI Express)
تعریف: باس پرسرعت برای اتصال کارت گرافیک، SSD و دستگاههای پرسرعت دیگر.
نسلها: PCIe 3.0 → 4.0 → 5.0 (هر نسل دو برابر سرعت نسل قبل)
مثال: PCIe 5.0 x16: حداکثر 64 GB/s پهنای باند
کاربرد: GPU ها، SSD های NVMe پرسرعت.
Lanes (خطوط PCIe)
تعریف: مسیرهای موازی انتقال داده در PCIe.
مثال: x16 = 16 خط موازی، x4 = 4 خط موازی
نکته: خطوط بیشتر = پهنای باند بیشتر برای انتقال داده.
DMI (Direct Media Interface)
تعریف: باس ارتباطی اختصاصی بین CPU و چیپست مادربرد.
نسلها: DMI 3.0 → DMI 4.0 (معادل PCIe 4.0 x8)
کاربرد: اتصال CPU به درگاههای SATA، USB، شبکه و سایر I/O های مادربرد.
UHD Graphics 770 / 730
تعریف: گرافیک مجتمع (iGPU) داخل پردازنده Intel.
کاربرد: نمایش تصویر بدون کارت گرافیک مجزا، رمزگشایی ویدئو، کارهای سبک گرافیکی
نکته: برای بازی سنگین کافی نیست، کارت گرافیک مجزا لازم است.
Branch Prediction (پیشبینی شاخه)
تعریف: تکنیک پیشبینی مسیر دستورات شرطی (if/else) قبل از اجرا برای جلوگیری از توقف Pipeline.
اجزا: BTB (Branch Target Buffer), PHT (Pattern History Table)
دقت: 95-99% در Core i9 مدرن
فایده: جلوگیری از اتلاف زمان در تصمیمگیریهای شرطی.
AVX-512 (Advanced Vector Extensions)
تعریف: دستورات SIMD پیشرفته برای محاسبات موازی با دادههای 512 بیتی.
کاربرد: پردازش تصویر، شبیهسازی علمی، یادگیری ماشین، رمزنگاری
قدرت: اجرای 16 عملیات اعشاری 32-بیتی همزمان در یک دستور
نکته: در E-cores پشتیبانی نمیشود، فقط P-cores.
Execution Units / Ports
تعریف: واحدهای محاسباتی تخصصی داخل هر هسته که دستورات را اجرا میکنند.
انواع: ALU (محاسبات صحیح), FPU (اعشاری), Load/Store (خواندن/نوشتن حافظه), Branch (شاخه)
Ports: مسیرهایی که دستورات از طریق آن به واحدهای اجرایی میروند (Port 0-11)
فایده: اجرای موازی چندین دستور در هر سیکل.
Store-to-Load Forwarding
تعریف: تکنیک ارسال مستقیم داده از دستور Store (نوشتن) به دستور Load (خواندن) بدون نوشتن در Cache.
فایده: کاهش تأخیر زمانی که دستور خواندن، داده نوشته شده توسط دستور قبلی را نیاز دارد.
نمونه: `x = 5; y = x + 1;` - مقدار x مستقیماً به دستور دوم فرستاده میشود.
Memory Disambiguation
تعریف: تشخیص اینکه آیا دو دسترسی حافظه به آدرسهای یکسان اشاره میکنند یا خیر.
فایده: امکان اجرای out-of-order دستورات حافظه بدون تداخل
مثال: Load میتواند قبل از Store قبلی اجرا شود اگر به آدرس متفاوت باشند.
FLOPS (Floating Point Operations Per Second)
تعریف: تعداد عملیات اعشاری در هر ثانیه - معیار قدرت محاسباتی.
واحدها: GFLOPS (میلیارد), TFLOPS (تریلیون)
مثال: Core i9-13900K با AVX-512: بیش از 2 TFLOPS
کاربرد: محاسبات علمی، شبیهسازی، یادگیری عمیق.
منابع و مراجع
- Intel® 64 and IA-32 Architectures Optimization Reference Manual
- Intel® Architecture Instruction Set Extensions Programming Reference
- Hennessy & Patterson, Computer Architecture: A Quantitative Approach (6th Edition)
- Agner Fog, "The microarchitecture of Intel, AMD and VIA CPUs"
- WikiChip - Intel Microarchitectures
- Various Intel Architecture Day presentations and whitepapers